最近 5 日分 / 今月の一覧
2016-09-08 Thu
■ Crowi v1.5.0 にリファラ抑制機能を付けてみた、ものの…… [Crowi]
Crowi は、認証付きの Wiki で、クローズドな環境で使われることが多いと思うんですが、外部サイトへリンクを張っていると、相手サイトにリファラが伝わるケースがあります。
これは、Crowi を https 化しても同様です。httpsサイト -> http サイトなら、ブラウザはリファラを相手に通知しないんですが、httpsサイト -> https サイトだと、ブラウザは通知してしまいます。
Let's Encrypt など、無料でドメイン認証(DV: Domain Validation) の証明書を発行してくれるところが出てきたので、ますますこの傾向は強まっていくものと思われます。
で、これを抑制しようと
Referrer を制御する
http://qiita.com/wakaba@github/items/707d72f97f2862cd8000
を参考に、ヘッダに
<meta name=referrer content="no-referrer">
を追加し、さらに id='revision-body-content' と id='preview-body' 内にある Aタグの属性に ref="noreferrer" を追加するような感じで実装してみました。
一応本家にフィードバックできるようにと、管理画面から Off/On できるようにしたんですが、
- 設定が mongod に保存されないのになぜか設定が切り替わる(Crowiをrestartしても!)
- 本来なら marked を override して実装すべきところを、DOM操作でごまかしてる
とか、きちんと理解してないが故にダメダメな感じで pull request するなんて以っての外!さて、どうしたものかと twitterで嘆いてたら、作者の方から反応があって、普通に本家が対応してくれそう!ということで、同じようにリファラの抑制機能が必要な人は、本家の対応を待つといいよ!
ともあれ、せっかくなので、
- 固定的にリファラを抑制するパッチ
- 管理画面から抑制を Off/On できるけど、挙動が謎なパッチで完全無保証というか当てるな危険というパッチ
の2種類置いときます。まぁどっちのパッチでもブラウザが対応してないとダメですけどね。
しかし、Crowi を今後使う上でも、いよいよJavascript もやっとかないとダメかなぁ……
2016-09-06 Tue
■ Crowi v1.5.0 にアップデートしてみた [Crowi]
Crowi v1.5.0 がリリースされました。
https://github.com/crowi/crowi/releases/tag/v1.5.0
なんと言っても、目玉は検索対応でしょう!(検索エンジンには Elasticsearch が使われます)
ということで、CentOS7 で Crowi v1.4.0 を利用している人向けに、Crowi 1.5.0 に上げる方法について下記に。
まずはElasticsearchをインストールしておきましょう。/etc/yum.repos.d/elasticsearch.repo を下記の内容で作成しておきます。
[Elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
また、plugin に kuromoji が必要なので、それもインストールしておきます(plugin のインストール後に、Elasticsearchの restart が必要です)
$ sudo su -
# yum update
# yum install java-1.8.0-openjdk elasticsearch
# cd /usr/share/elasticsearch
# bin/plugin install analysis-kuromoji
# systemctl restart elasticsearch
次に Crowi を止めて、バックアップを取ります。
$ sudo systemctl stop crowi
$ mkdir -p ~/backup/public
$ mongodump --out ~/backup/2016-09-06_01
$ rsync -avz $SOMEWHERE/crowi/public/ ~/backup/public/
下記、以前書いた "Crowi を CentOS7 にインストール" [2016-05-13-1] に従ってインストールしたと仮定して記載していきます。
$ cd /usr/local/src/crowi
$ git pull --tags
$ git checkout v1.5.0
$ npm install
次に、/etc/sysconfig/crowi に下記 1行を追加します。
ELASTICSEARCH_URI=http://127.0.0.1:9200
Crowi を起動します。
$ sudo systemctl start crowi
あとはログインして、"管理" -> "検索管理" -> "Build Now" をクリックすれば、以降検索が可能となります。
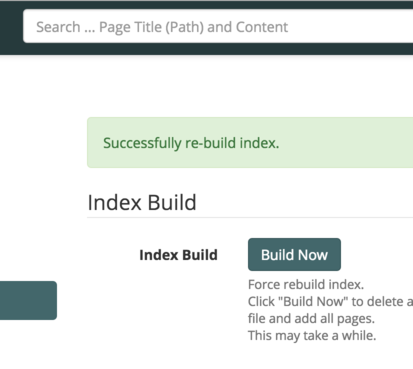
地味によい改善としては、ページの削除、セキュリティの強化なども。ただ今回の更新でも、管理者からユーザのパスワードの上書き変更ができないので、今後の運用を考えると、ちょっとドキドキ……みんな、パスワード忘れました!とか言い出さないでね(DBを直接書き換えるとか、あんまりやりたくない)
2016-05-14 Sat
■ SiteGuard Lite の出力ログを Webalizerで解析 [Linux][Security]
もう1つ、会社のブログに記事が追加されてます。
SiteGuard Lite の出力ログを Webalizer で解析してみる
https://toe.bbtower.co.jp/20160428/191/
SiteGuard Lite って、機能縮退版って意味なのかと思ってたら違うんですね。ゲートウェイ型ではなく、ホストにインストールするやつを SiteGuard Lite って読んでるそうです。
SiteGuard Lite は、管理画面もついてて、ログも表示されるんですが、それを集計し、グラフ化する機能は別製品になってます。とは言いながらも、マニュアルに記載があるように、Webalizerで解析、グラフ化するためのパッチも用意されてます。
ただ、ベースが古すぎて、最新版の webalizer-2.23-08 では使えなかったので、使えるように書き換えてみました。動作保証無しですが、よろしければ、上記URLからパッチを入手してみてください。
とにもかくにも、パッチ公開をご快諾頂けたジェイピー・セキュアさんには、重ね重ね感謝です :-)
■ 負荷テストツールの tsungについて [Linux]
こっちでお知らせするのを忘れてましたが、会社のブログに記事を追加しました。
負荷テストツールの tsung を使ってみる
https://toe.bbtower.co.jp/20160407/93/
tsung は、Erlang で書かれたマルチプロトコル対応の負荷テストツールで、結構気軽にクライアントを増やせるので、なかなかいいです。
2016-05-13 Fri
■ Crowi のいいとこ、今後に期待するところ [Crowi]
まだ使い始めたばかりですが、期待していないところでこれいいな!と思ったところを
- 記事の公開範囲を指定できる
- 公開、自分のみ, リンクを知っている人のみ、から選べる
- プレゼンモードがある
- 意外といい感じ
- 記事が permalink を持ってる
- URLパスは変更できるけど、内部的には permalink 持ってるので、そっちを使えばURLパス変更しても大丈夫。
- "新規メモを作成" で簡単に始められる
- URLをあれこれ考えなくて、あとで自由にパスを移動できる。さくっと記述に移れるのはいいですね。
あともうちょっとと言うところ。
- パスワードリカバリー機能がない
- メール・アドレスのドメインで登録を制限できるが、所有者確認がなされない
- アカウト承認時の通知機能がない
- プレビューは要らないので、画像ファイル以外もアップロードしたい(patch, text, PDF, ppt, xls...)
- アップロードしたファイルの削除機能が欲しい
- LDAP認証に対応していない
- グループ単位に閲覧制限が掛けられない(plugin に頼らずこれができる Wiki って見たことないけど)
- 検索機能がない(これは対応予定だそうです。楽しみですね)
そういう意味で、ちょっと管理系が弱いかな?あとは、Markdown Extra 記法に対応してくれると嬉しいです。
不満点はこれぐらいで、なかなか気持よく入力できます。グループWiki としては秀逸な部類に入るんじゃないでしょうか。
いやーいいですよ、Crowi :-)
■ Crowi を CentOS7 にインストール [Crowi]
Crowi 1.4.0 がリリースされました。
https://medium.com/crowi-book/crowi-v1-4-0-43762793741d#.pxjx1gk0k
Crowiは、Markdown 記法を用いた Wikiシステムです。
検索機能は残念ながら見送られたようですが、それは次回リリースに期待ということで。
今回は、これを CentOS7 にインストールしてみます。SELinux は Permissive もしくは Disable前提です。
まずは必要なパッケージを以下に。
# yum -y install epel-release
# yum -y install git mongodb-server gcc gcc+ mongodb
つぎに mongo 関連です。
# systemctl start mongod
これで mongoサーバが起動されますので、mongo shell で crowi用のアカウントを作成します。
$ mongo
\> use crowidb
switched to db crowidb
\> db.createUser({user: "ユーザ名", pwd: "パスワード", roles: [{role: "readWrite", db: "データベース名"}]})
Successfully added user: {
"user" : "crowi",
"roles" : [
{
"role" : "readWrite",
"db" : "crowidb"
}
]
}
ユーザができたかの確認
\> use admin
\> db.system.users.find()
{ "_id" : "crowidb.crowi", "user" : "crowi", "db" : "crowidb", "credentials" : { "MONGODB-CR" : "2d47a95cc02ac854bd6cc4ce2496682c" }, "roles" : [ { "role" : "readWrite", "db" : "crowidb" } ] }
で、肝心の node.js なんですが、CentOS7 のは古いのでうまく動きません。node.js 4.2 系である必要があります。とりあえず node.js 4.3.3でも動いたので、私は 4.4.3 をインストールしました。
# rpm -Uvh https://rpm.nodesource.com/pub_4.x/el/7/x86_64/nodejs-4.4.3-1nodesource.el7.centos.x86_64.rpm
Crowi の clone と npm install
$ mkdir src
$ cd src
$ git clone --depth=1 -b v1.4.0 https://github.com/crowi/crowi
$ cd crowi
$ npm install
npm install はそれなりに時間がかかります。で、ここからは CentOS7 固有の話。systemd で起動できるようにします。
# touch /etc/sysconfig/crowi
# chmod 600 /etc/sysconfig/crowi
# vi /etc/sysconfig/crowi
PORT=3000
#NODE_ENV=
MONGO_URI="mongodb://ユーザ名:パスワード@localhost/DB名"
#REDIS_URL
PASSWORD_SEED=hgoehogehoge
#SECRET_TOKEN=
FILE_UPLOAD=local
このファイルで記述したものが環境変数として取り込まれることになります。MONGO_URIで指定しているユーザ名、パスワード、DB名は、db.createUserで指定したものです。PASSWORD_SEED は適当なランダム文字列を指定しておきましょう。
# vi /etc/systemd/system/crowi.service
[Unit]
Description=Crowi - The Simple & Powerful Communication Tool Based on Wiki
After=network.target mongod.service
[Service]
WorkingDirectory=/home/vagrant/src/crowi
EnvironmentFile=/etc/sysconfig/crowi
ExecStart=/usr/bin/node app.js
[Install]
WantedBy=multi-user.target
これを systemd に反映させます(WorkingDirectoryは、ソースコードを展開したディレクトリ名です。適当に修正してください)
# systemctl daemon-realod
あとは
# systemctl start crowi
で起動します。3000番ポートを Listen しているので、適当にfirewalld でフィルタを開けてください。
なお、
vi ~/src/crowi/lib/crowi/express-init.js
の
config.crowi['app:url'] = baseUrl = .....
ということころは、明示的に書きなおしていた方が、共有用のリンクとかで幸せにになれるかもしれません。
また、データバックアップは、~/src/crowi/public/upload 以下と mongodb の dump データでいいはず。
2016-04-11 Mon
■ tsung について [Benchmark]
会社のブログで新しいエントリーが公開されました。
負荷テストツールの tsung を使ってみる
https://toe.bbtower.co.jp/20160407/93/
tsung は erlang で書かれたツールです。JMeter ほど細かな制御ができるわけではないですが、大きな負荷を掛けたいときには便利なツールです。特に設定をしなくても、cookie とかも勝手に食ってくれたかと思うので、ページ遷移にも追随してくれるはずです。
■ 会社で技術ブログ書き始めました [よもやま]
そういえば、会社でもブログを書き始めました。
ドキュメントで利用可能なIPアドレスなど
https://toe.bbtower.co.jp/20160331/132/
真面目に調べているうちに肥大化しました。多分、この手の話題を扱った記事としては、一番詳しく掛けたんじゃないかなぁと思ってます。よろしければご一読を。
| IPv4/IPv6 meter |
検索キーワードは複数指定できます
| 思ったより安い……時もある、Amazon |
カテゴリ
- Ajax (14)
- Amazon (1)
- Apache (28)
- Backup (4)
- Benchmark (5)
- Blog (3)
- Book (22)
- C (10)
- CGI (2)
- CPAN (8)
- CSS (2)
- Catalyst (8)
- CentOS (2)
- Chalow (11)
- CheatSheet (3)
- Computer (2)
- Crowi (4)
- DB (8)
- DBIC (10)
- DNS (6)
- Debian (31)
- Design (5)
- Django (9)
- Docker (7)
- Emacs (22)
- English (13)
- Excel (3)
- FileSystem (3)
- Firefox (19)
- Flash (2)
- Food (25)
- Framework (3)
- GTD (4)
- Gadget (6)
- Gmail (1)
- Google (19)
- HTML (2)
- Hacker (1)
- Health (22)
- Howto (5)
- IBM (3)
- IETF (2)
- IPv6 (45)
- JANOG (9)
- Java (8)
- Javascript (27)
- LDAP (4)
- Language (4)
- Life (4)
- Lifehack (3)
- Linix (1)
- Linux (129)
- Lisp (2)
- Mac (8)
- Mail (3)
- Manuscript (1)
- Monitoring (1)
- Munin (1)
- MySQL (23)
- Network (19)
- PHP (13)
- Perl (69)
- PostgreSQL (8)
- Programing (5)
- Python (42)
- RPM (1)
- RSS (4)
- React (1)
- RedHat (2)
- Regexp (3)
- Ruby (9)
- Samba (1)
- Scheme (3)
- Security (54)
- Server (4)
- Shell (6)
- Storage (6)
- Subversion (9)
- TAG (2)
- TIPS (26)
- TLS (1)
- Test (6)
- ThinkPad (9)
- Tomcat (3)
- Tools (18)
- Trac (9)
- Troubleshooting (2)
- Tuning (6)
- VMware (12)
- VPN (2)
- Vault (4)
- Vim (3)
- Vmware (5)
- VoIP (1)
- Vyatta (2)
- Web (28)
- WiFi (2)
- Wiki (3)
- Windows (10)
- XML (2)
- XSLT (1)
- Xen (2)
- XenServer (11)
- Zabbix (1)
- junoser (1)
- linkdraw (1)
- python (1)
- raspberry (2)
- skark (1)
- ssh (4)
- systemd (1)
- あとで読む (5)
- その他 (67)
- よもやま (29)
- アサマシ (24)
- イベント (4)
- ゲーム (1)
- ストリーム (2)
- セマンティック (1)
- ダイエット (1)
- ネタ (98)
- 仮想化 (11)
- 開発 (73)
- 環境 (3)
- 管理 (7)
- 休暇 (5)
- 携帯 (8)
- 検索 (3)
- 酒 (3)
- 小物 (10)
- 投資 (1)
- 文字コード (6)
- 勉強会 (1)